
AIの品質問題点をソフトウェア技術の観点から解説する
中島 震(国立情報学研究所 名誉教授)
中島先生は、放送大学大学院の情報学プログラムの中で「ソフトウェア工学(‘25)」を担当されています。先生の講義ではソフトウェア開発を工学的に行うためのプロセスや手法、品質や生産性、進化などに関する技術について学べます。ソフトウェア開発で生じる問題について学び、開発のプロセスに沿って問題点を整理し、問題解決への技術を理解していきます。
本記事では、ソフトウェア工学が専門で、「形式手法やソフトウェアテスティングの技術」「機械学習を対象としたAIリスクマネジメント」を研究されている中島震氏へのインタビューをもとに作成しています。
第9回では、生成AIの技術で作成した偽情報、捏造されたデータの危険度、怖さについて解説いただきました。
第10回となる今回は、第8回ニュースレター内では解説しきれなかった、LLMを本格的に利用する前の準備実験の例を紹介いただき、実験結果を解説いただきます。
第10回 LLMと上手に対話する(3)〜 相手に合わせた話し方 〜
LLMを活用したチャットボットは有能なアシスタントといわれています。ところで、そもそも、聞きたいことを、LLMは知っているのでしょうか。LLMが、どういう知識を持つかで、会話の仕方が変わります。
会話の相手
調べものを誰かに頼む場合を考えてください。依頼相手が何を知っているかがはっきりしていると、お願いしやすいです。たとえば、研究室に配属されたばかりの新入生が相手だと、丁寧な説明が必要かもしれません。長く同じ分野の研究を続けている上級生であれば、要点だけを端的に示せば良いでしょう。相手に合わせて、内容を工夫します。
LLMは、多様な学習データで訓練されており、「百科全書」のように膨大な知識を持っています。いや、持っている筈です。内部の知識は訓練に用いた学習データに左右されるので、聞きたいことに関する情報をLLMが持っていないかもしれません。では、LLMは何を知っているのでしょう。仮に多様な知識を持つとしても、その知識を活用し適切な受け答えを返す能力、推論する能力を持つのでしょうか。
部品の機能
自然言語アプリケーションシステムを開発する場合を考えます。LLMは自然言語処理のプログラム部品です。LLMをシステムに組み込む方法をデザインするには、入力に対して、どのような情報を出力するのか、といった部品の機能振舞いを知る必要があります。
自然言語のプロンプトを入力すると自然言語のコンテンツが出力される、というだけでは、そのLLMが適切な部品なのかを判断できません。自然言語処理の基本は、文法構造上正しいテキストを出力することですが、「百科全書」として適切な情報を返して欲しいです。従来のプログラム部品と違い、LLMの機能振舞いは複雑で部品としての諸元が不明です。
内部知識の確認
チャットボットとして対話の相手にするか、あるいは、ソフトウェア部品としてシステムに組み込むか、いずれの場合も、本格的に利用する前準備として、話題にしたい分野に精通しているかを確認するのが良いでしょう。答えが正しいか、妥当か、といった判断が容易な質問を準備し、出力される内容を調べます。何回かやりとりすると、LLMが持つ能力(ケーパビリティ)がわかってくるように思えます。
以下、少し長いです。お急ぎであれば、最後の「メタ認知」にお進みください。
実験の問題例
具体例として、ソフトウェア工学の分野から話題を選び、手元のチャットボット(LLM)のケーパビリティを調べました。考える話題は、ソフトウェア製品ファミリーのデザインを検討する時に用いる図式のフィーチャーモデル文献[1]です。作成したフィーチャーモデルを分析することが目的で、矛盾していないか、顧客が期待する製品を構成できるか、全く使われない要素が混入していないか、などを確認します。
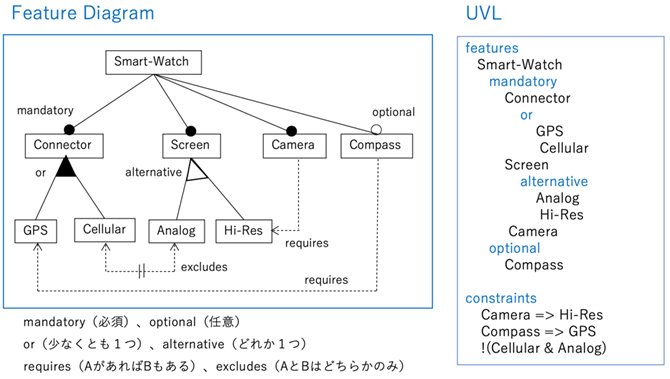
手元のLLMがフィーチャーモデルに関する知識を持つかを調べる実験を行いましょう。大きく分けて2つの観点があります。第1に、フィーチャーモデルという考え方、フィーチャー図の構成要素や表現方法、フィーチャーモデルの分析操作といった知識を持つかです。第2に、与えたフィーチャーモデルに対して分析操作を実行できるかです。前者が「百科全書」的な静的な知識である一方、後者は分析アルゴリズムあるいは推論のような情報操作する知識が関わり「動く百科全書」としての能力と言えます。
実験結果のまとめ
LLMを利用したチャットボットに繰り返し問いを投げかけたところ、面白い状況に遭遇しました。以下、実験結果を簡単にまとめます。
フィーチャーモデルは重要なモデリングの方法で、表記法を標準化する活動が進められました。現在、UVL文献[2]と呼ばれるテキスト形式が有力です。一連の質疑応答から、LLMは、UVLについての「百科全書」的な知識を持つことがわかりました。また、どのような分析操作があるかを質問したところ、20種類の操作を一覧しました。
次に、UVLの具体例を与えて分析操作を実行できるか試すと、期待した通りの分析結果を返しました。また、妥当でないUVLの記述例に対して入力が不正であることを指摘したり、実施した分析の進め方について適切に回答したりしました。一方、たとえば、全く使われない要素の有無を調べる分析(Dead features)では、指示していないにも関わらず、修正案を提示するなど、余分な情報を含みました。グライスの量の原則(第7回ニュースレターを参照)から適切さを欠くものの、概ね「動く百科全書」として役立つことがわかります。
この実験から、手元にあったLLMは、UVL表記のフィーチャーモデルを表現し分析する際に必要な知識を持つことが確認できました。このLLMを部品に使って、フィーチャーモデル分析支援ツールを容易に開発できそうです。
メタ認知
20種類の操作の中には、フィーチャーモデル分析と考えられない項目がありました。何処かで誤りが混入していて、グライスの質の原則を満たしません。その理由が気になります。
そこで、何度か問い合わせたところ、「フィーチャー」という用語の字面だけから情報を集めた、と推測できました。詳しく調べるように指示すると、外部情報を入手しようと自動的にWeb検索を行いました。検索上位に出現したWebページは機械学習の「フィーチャー」に関したもので、「機械学習」という語が対話の文脈を規定する重要なキーワードであるとしました。当初の「フィーチャーモデル」から話題が外れ、グライスの関連の原則に反することになります。「文脈からの逸脱」のハルシネーション(第3回ニュースレターを参照)と同じ状況になったことが、誤り混入の理由と思われます。
最後に、文脈から逸脱した理由を問うと、「『同じ用語でも文脈で意味が変わる』という『メタ認知』を持たないから」、と出力しました。このように答えるには、自分の考えた道筋や対話が期待の方向に進んでいるか否かを把握する「メタ認知」を持つ必要があります。ということで、先の出力内容はLLM自身が「考えた答え」ではなく、『LLMはメタ認知を持たない』という内容の「百科全書知識」に基づいて回答したように思えてきます。
利用者の私たちが、LLMの「メタ認知」の役を引き受け、話題から外れないように、対話の流れを制御すべきですね。
参考文献
[1] 岸 知二:ソフトウェア・アーキテクチャ設計、『[改訂版] ソフトウェア工学』、第7章、放送大学教育振興会 (2025).
[2] David Benavides, Chico Sundermann, Kevin Feichtinger, José A. Galindo, Rick Rabiser, and Thomas Thüm, UVL: Feature modelling with the Universal Variability Language, Journal of Systems and Software, Volume 225, 112326 (2025).
次回の予告
中島先生の第11回ニュースレターでは、LLMの訓練に用いた学習データは、どのような内容なのか、公開されている学習用コーパスの中身を調べ、解説いただきます。
中島震先生、山口高平先生のニュースレターバックナンバーはこちら
中島先生の著書はこちらです
■「AIアルゴリズムからAIセーフティへ」
中島 震 (訳) (原著:O.サントス, P.ラダニエフ)
丸善出版 2025年3月 (ISBN: 9784621310328)
■「AIリスク・マネジメント」
中島 震
丸善出版 2022年12月 (ISBN: 9784621307809)
■「ソフトウェア工学から学ぶ機械学習の品質問題」
中島 震
丸善出版 2020年11月 (ISBN: 9784621305737)