
AIの品質問題点をソフトウェア技術の観点から解説する
中島 震(国立情報学研究所 名誉教授)
中島先生は、放送大学大学院の情報学プログラムの中で「ソフトウェア工学(‘25)」を担当されています。先生の講義ではソフトウェア開発を工学的に行うためのプロセスや手法、品質や生産性、進化などに関する技術について学べます。ソフトウェア開発で生じる問題について学び、開発のプロセスに沿って問題点を整理し、問題解決への技術を理解していきます。
本記事では、ソフトウェア工学が専門で、「形式手法やソフトウェアテスティングの技術」「機械学習を対象としたAIリスクマネジメント」を研究されている中島震氏へのインタビューをもとに作成しています。
第10回では、過去のニュースレター内で解説しきれていなかった、LLMを本格的に利用する前の準備実験の例を紹介いただき、実験結果を解説いただきました。
第11回となる今回は、大規模言語モデル(LLM)を構築している学習用コーパスの構築方法とその中身について解説いただきます。
第11回 学習データセットの中身(1)〜 LLMの学習用コーパス 〜
大規模言語モデル(LLM)の訓練に使用する学習データは、膨大な量のテキストからなるコーパスをもとに構築されます。多種多様な用例を使ってモデル訓練することで、単語の並び方や使われ方など、自然言語を取り扱う一般的な知識を得ます。では、学習用コーパスの中身は、どのようなものなのでしょうか。
言語処理の知識
自然言語を理解し生成するには、文を構成する規則(文法)や多くの語彙(辞書)の情報が必要です。言語モデル訓練は、実際の使い方(用例)を収集したコーパスから学習データを構築し、その具体的なデータから言語処理に必要な知識を帰納的に学習することです。
言語モデルのそもそもの目的は、自然言語の理解と生成に必要な知識(メタ言語知識)を学習することでした。正確性を向上しようとして用例を増やすに連れて、語彙やイディオムといった「断片的な知識」だけでなく、各々の用例が表す内容(伝達意味)を学習していることがわかりました。メタ言語知識を学習する過程で、副産物として「百科全書知識」を獲得したといえます。
LLMが学習した内部知識を、便宜上、メタ言語知識と百科全書知識に分けましたが、両者が明確に区別されているわけではありません。また、情報の源は学習データですから、コーパスにない情報を持ちません。適切な学習データを用いLLMが期待通りの百科全書知識を持つとした場合、後は、必要に応じて知識をうまく読み出せれば良いことになります。
インターネットから収集
学習データは広範なテキストからなるコーパスがもとになります。効率良く、テキスト収集するには、インターネット上で公開されている多種多様な情報を活用すればよいでしょう。
Common Crawl(1)という非営利団体が、2011年からWebページを定期的に自動収集し、大規模テキストデータを蓄積しています。また、研究用途に公開していることから、LLMの学習用コーパスに使うことが提案されました。そのまま使えるわけではなく、Common Crawlからテキストデータを選択し、学習に不要な情報を除去するといった前処理を行なってから、LLMの訓練に使います、
実際、Common Crawlをベースとする学習用のコーパスが構築され、LLMの訓練に使われています。2019年頃、研究目的で作られたコーパスあるいは学習データが公開されました。その後の商用ベースLLMでは、学習データの内容を非公開とすること多いです。事業者がビジネスをする上で秘匿したいノウハウを含む場合があることが理由のひとつです。一方、学習データの情報がわからないと、そのLLMが、どのような知識を持つか直ちにわかるわけではないです。メタ言語知識を持つことは共通でしょうが、どのような用例を学習したかで百科全書知識は異なります。
学習用コーパスの例
Colossal Clean Crawled Corpus (C4)文献[1]は、Google社が2019年に開発し公開した学習用のコーパスで、英語の文書のみを含みました。305GB規模のテキストで、主なソースは、特許明細書(2)、英語版Wikipedia、電子書籍を集めたToronto Booksコーパス、巨大掲示板型SNSのReddit(3)から収集したWebテキスト、などです。Redditからはユーザーの「いいね」評価が高い内容のWebテキストを選ぶことで適切さに欠けるテキストを避けました。技術的な文書や用語解説、日常的な文まで、多様な英語表現を集めていることがわかります。また、NGワードを含むテキストを事前に除去するといった工夫をしたものの、人種的な偏見が残ると分析されています文献[2]。
もう一つの例としてPile文献[3]を紹介します。研究開発が目的の非営利団体Eleuther AIが開発し公開している学習データで、825GB規模のテキストです。C4など既存の研究から、高機能なLLMモデル訓練では、多様な用例を集めた学習用のコーパスが有用なことがわかりました。そこで、Pileは、ソースの特徴が異なる22個のデータセットを整理しまとめました。Common CrawlからのテキストやRedditの評価を参考に収集したテキストならびに英語版Wikipediaに加えて、学術論文のアブストラクトやarXivプレプリント、公的な公開文書(特許明細書、裁判関連文書)、パブリックドメインの電子化古典書籍、電子書籍などからなります。また、Youtube動画のキャプションやGitHubのソースコードといった多様なテキストを含みます。
Pileは、他プロジェクトで開発された研究目的のデータセットも含むことから、公開された2020年時点での、LLM学習用コーパスのスナップショットといえます。以降の研究あるいはビジネスの違いを問わず、英語ベースの学習用コーパスの基準と考えて良いでしょう。
(2):https://patents.google.com
(3):https://www.reddit.com/
学習データの枯渇
その後、インターネットから大量のテキストを収集する方法に問題があることが指摘されました。ひとつは、インターネットが膨大な情報を持つとしても、無尽蔵ではないことです。また、C4やPileは、事前処理を行って、学習データとして相応しい英語テキストを収集しました。入手可能な情報の全てを利用できるわけではありません。
このデータ枯渇問題への対策として、LLM生成テキストを学習データに使う方法を思いつきます。LLMの技術発展と共に、どのテキストが人手作成か、LLM生成か、を判定することが難しくなり、生成テキストの品質が向上してきました。これを学習データとして使うという発想です。実際、LLM生成テキストが既にインターネット上で増えているともいわれています。
ところが、生成テキストは、英語の場合ですが、特徴的なパターンを持つことがわかっています文献[4]。LLMの生成コンテンツは学習コーパスに依存しますし、そのようなコンテンツを学習コーパスに追加する場合、似たような学習データが増える一方で多様性が減少します。これを繰り返すと、LLMに期待される幅広い知識が消失し、同じようなコンテンツ群だけを生成するようになる恐れがあります。このような「モデル崩壊」が生じることが理論的な分析でわかっています文献[5]。
実用的なLLM開発
チャットボットなど、私たちが利用するアプリケーションシステムに組み込まれたLLMは、複数の学習ステージを経て開発されます(図を参照)。
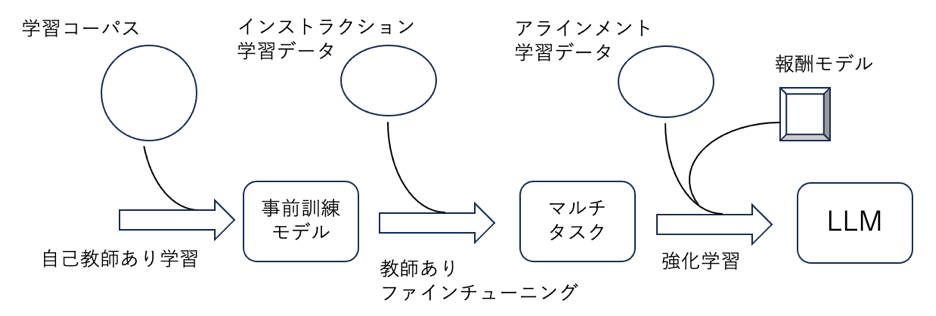
今回、注目したのは、上図の最も左側に相当し、インターネットなどから収集した学習用コーパスをLLM訓練に利用するという話題でした。その後段のステージで準備する学習データは、利用者からみたLLMの使い方と強く関わり、たとえば、チャットボットの振る舞いに大きく影響し、製品の使い勝手に関わります。後段の学習データは、LLM開発ビジネス主体のノウハウによるところが大きく、公開されないことが多いです。
参考文献
[1] Colin Raffel, et al.: Exploring the limits of transfer learning with a unified text-to-text transformer, Journal of Machine Learning Research 21, pp.1-67 (2020).
[2] Jess Dodge, et al.: Documenting LargeWebtext Corpora: A Case Study on the Colossal Clean Crawled Corpus, arXiv:2104.08758v2 (2021).
[3] Leo Gao, et al.: The Pile: An 800GB Dataset of Diverse Text for Language Modeling, arXiv:2101.00027 (2021).
[4] https://en.wikipedia.org/wiki/Wikipedia:Signs_of_AI_writing
[5] Ilia Shumailov, et al.: The Curse of Recursion: Training on Generated Data Makes Models Forget, arXiv:2305.17493v3 (2024)
次回の予告
中島先生の第12回ニュースレターでは、学習用コーパス関連の話題を引き続き紹介します。特に、収集した用例が暗黙に表す言語文化とLLMの関係を考え、解説いただきます。
中島震先生、山口高平先生のニュースレターバックナンバーはこちら
中島先生の著書はこちらです
■「AIアルゴリズムからAIセーフティへ」
中島 震 (訳) (原著:O.サントス, P.ラダニエフ)
丸善出版 2025年3月 (ISBN: 9784621310328)
■「AIリスク・マネジメント」
中島 震
丸善出版 2022年12月 (ISBN: 9784621307809)
■「ソフトウェア工学から学ぶ機械学習の品質問題」
中島 震
丸善出版 2020年11月 (ISBN: 9784621305737)