
AIの品質問題点をソフトウェア技術の観点から解説する
中島 震(国立情報学研究所 名誉教授)
中島先生は、放送大学大学院の情報学プログラムの中で「ソフトウェア工学(‘25)」を担当されています。先生の講義ではソフトウェア開発を工学的に行うためのプロセスや手法、品質や生産性、進化などに関する技術について学べます。ソフトウェア開発で生じる問題について学び、開発のプロセスに沿って問題点を整理し、問題解決への技術を理解していきます。
本記事では、ソフトウェア工学が専門で、「形式手法やソフトウェアテスティングの技術」「機械学習を対象としたAIリスクマネジメント」を研究されている中島震氏へのインタビューをもとに作成しています。
第12回では、複数言語の用例を収集した多言語コーパスの構築について解説いただきました。
第13回となる今回のニュースレターでは生成AIと著作権の問題点について解説いただき、生成AIやLLMを利用する上で知っておくべき情報を説明いただきます。
第13回 学習データセットの中身(3)〜 著作物の学習利用〜
チャットボットの広がりと共に、機械学習AIのモデル訓練で、権利者の利用許可なく著作物を使って良いかの問題が再燃しました。「生成AIと著作権」というテーマで、著作権法が関係し法律の専門家の判断が必要な話題です。ここでは、生成AIやLLMを利用する上で知っておくと良いことを整理しました。
海賊版DVD
映画などの映像DVDを考えます。映像作品(著作物)をデジタル圧縮した情報(符号化情報)を保存した媒体で、DVDプレイヤーを用いることで再生映像(出力物)を楽しむことができます(図)。
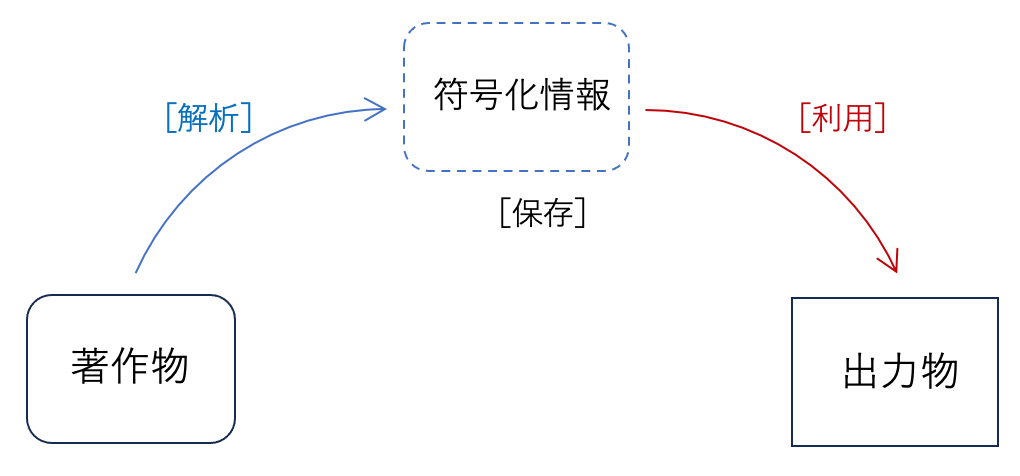
映像作品を著作権者の許可なく無断で作成したDVDは海賊版といわれ、製造・販売は著作権を侵害します。海賊版を正規のDVDと偽って販売すると、不正競争防止法違反になることがあります。海賊版DVDは著作物の無断利用であって、著作権者の利益を侵害します。明らかに違法ですね。
大量のデータが必要
機械学習では、モデル訓練に大量の学習データを用います。たとえば、LLMでは、インターネットから収集した情報を利用しました。この時、学習データに書籍などの著作物が紛れ込んでいるかもしれません。大量に自動収集しているので、著作権者の許諾を得ることが難しいです。
著作権法の目的は、表現活動と権利保護のバランスを保つことです。著作者の権利を守るとともに、新たな表現活動を促進することが目的です。著作権者に不利益にならない範囲で、訓練済みモデルが新たな表現活動を生み出すのであれば、著作物の学習データ利用を制限しない枠組みが望ましいでしょう。
日本の著作権法には、「著作物に表現された思想又は感情の享受を目的としない利用(30条の4)」の規定があります(文献[1] 第V部第5章)。特に、2号では、情報解析に際して、利用許諾を得る必要がないとしています。モデル訓練は情報解析の特別な場合に相当するとし、この条項を根拠に「日本は機械学習のパラダイス」といわれたことがありました。
モデルの内部情報
「情報解析」や「モデル訓練」は、先の図の「解析」である、という立場です。訓練済みモデルは「符号化情報」ですが、映像DVDとは異なり、「保護されない情報」を表すとします。たとえば、絵画の真贋判定する学習タスクに、著作物をモデル訓練に用いる場合を考えましょう。この時、「符号化情報」は絵画にみられる筆使いなどの特徴になり、「出力物」は贋作か否かの判断結果です。「保護される情報」の絵画を記憶しているわけではないとしてよいでしょう。学習タスクに応じて訓練の仕方が違うので、保存される情報(モデルの内部情報)が異なり、この真贋判定では、享受を目的としない利用といえます。したところ、答えが定まります。
生成AIの登場と共に、著作権との関係が複雑化してきました。たとえば、画像生成AIでは、大量の絵画を学習データに用いてモデル訓練します。この「解析」は、真贋判定タスクの場合と似ているのですが、訓練に用いた絵画に似た画像を「出力物」として生成可能なことが大きな違いです。生成画像が許可なく広く流布されると、著作権者の権利を侵害する恐れが生じます。30条の4に但し書きがあり「当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない」とし、情報解析が許可されません。
変容力のある利用
米国では、フェアユース法理にしたがって、著作物の公正な利用(fair use)は著作権を侵害しないとしています(文献[1] 第XII部第9章、文献[2] 第4章)。また、具体的な事案がフェアユースにあたるかを判断する際に以下の4つの要件を考慮します。
- (1) 利用の目的および性格
- (2) 利用される著作物の性質
- (3) 利用される部分の量と実質性
- (4) 利用される著作物の潜在的な市場に与える影響
フェアユース法理は、上記の4つの要件を中心として総合的に判断されるべきことで、これまでに裁判例が蓄積されています。概ね、(1)に注目した「変容力のある利用(transformative use)」と(4)に関わる「市場の代替性(market substitution)」が議論の中心になっているようです。
「変容力のある利用」は、元の著作物と異なる目的を達成するか否かという見方で、図の「出力物」が持つ性格に着目します。先に述べた絵画の真贋判定タスクは、絵画の鑑賞という著作物の目的とは異なる利用であって、「変容力のある利用」と考えることができそうです。また、元の著作物に類似した絵画を生成するわけではないので、画家に経済的な不利益をもたらすこともないでしょう。
生成AI技術の発展
生成AIと著作権の関係の時間的な流れを振り返りましょう。日本での30条の4関連の議論は2015年に始められました。著作権団体へのヒアリングを経て、2017年にまとめられた報告書をもとに改正案が作成されたということです。
さて、画像生成AIの研究論文(GAN)が公表されたのは2014年です。ついで、2016年頃から、訓練データがモデル内に記憶されるか、特定データが訓練に使われたかを知ることが可能か(メンバーシップ攻撃)といった研究が進められました。2019年に言語モデルが訓練に用いた文字列をそのまま記憶(逐語記憶)、2023年に画像生成の拡散モデルが訓練データを記憶など、さまざまな生成AIモデルで同様な記憶の問題を生じることが実験で確認されました。また、2025年には、広く流通しているLLMが、特定の小説の42%を記憶していることが実験で確認されました(文献[3])。
以上の経緯から、日本で30条の4が施行された後に、生成AIに対する技術面からの理解が進んだことがわかります。今、新たな視点から、著作物の情報解析に関わる議論を深める必要があるのかもしれません。実際、2024年に文化庁が「AIと著作権」の関係を説明する文書(文献[4])を公開しています。(https://www.bunka.go.jp/seisaku/chosakuken/aiandcopyright.html)
ご一読ください。
参考文献
[1] 作花文雄:詳解著作権法[第6版]、ぎょうせい (2022).
[2] 上野達弘、奥邨弘司(編著):AIと著作権法、勁草書房 (2024).
[3] A. Feder Cooper et al.: Extracting Memorized Pieces of (Copyrighted) Books from Open-weight Language Models, arXiv:2505.12546 (2025).
[4] 文化審議会著作権分科会法制度小委員会「AIと著作権に関する考え方について」(令和6年3月).
次回の予告
中島先生の第14回ニュースレターでは、「情報解析」に関連した最近の考え方を紹介、解説いただきます。お楽しみに。
中島震先生、山口高平先生のニュースレターバックナンバーはこちら
中島先生の著書はこちらです
■「AIアルゴリズムからAIセーフティへ」
中島 震 (訳) (原著:O.サントス, P.ラダニエフ)
丸善出版 2025年3月 (ISBN: 9784621310328)
■「AIリスク・マネジメント」
中島 震
丸善出版 2022年12月 (ISBN: 9784621307809)
■「ソフトウェア工学から学ぶ機械学習の品質問題」
中島 震
丸善出版 2020年11月 (ISBN: 9784621305737)