
AIの品質問題点をソフトウェア技術の観点から解説する
中島 震(国立情報学研究所 名誉教授)
中島先生は、放送大学大学院の情報学プログラムの中で「ソフトウェア工学(‘25)」を担当されています。先生の講義ではソフトウェア開発を工学的に行うためのプロセスや手法、品質や生産性、進化などに関する技術について学べます。ソフトウェア開発で生じる問題について学び、開発のプロセスに沿って問題点を整理し、問題解決への技術を理解していきます。
本記事では、ソフトウェア工学が専門で、「形式手法やソフトウェアテスティングの技術」「機械学習を対象としたAIリスクマネジメント」を研究されている中島震氏へのインタビューをもとに作成しています。
第13回では、生成AIと著作権の問題点の中から、生成AIやLLMを利用する上で知っておくべきことを解説いただきました
第14回となる今回のニュースレターでは、前回ニュースレターに続き、生成AIと著作権の問題について解説いただきます。今回は著作物の類似性と依拠性の観点からの解説です。
第14回 学習データセットの中身(4)〜 著作物の学習利用と生成コンテンツ〜
生成AIはモデル訓練で用いた学習データに似たコンテンツを出力します。学習データが既存の作品を含む場合、作者などの権利を侵害する恐れがあります。
類似性と依拠性
「似た作品」が著作権を侵害するかどうかの議論では、見た目が似ている「類似性」だけでは片手落ちです。侵害の疑いのある作者が元の著作物の表現を参考にしたか(「依拠性」)を確認します。創作活動が全く独立に行われた結果、類似性の高い2つの作品が、偶然、生み出されるかもしれません。単に似ているというだけでは著作権侵害になりません(文献[1]第IV部第1章)。
生成AI訓練の目的は、学習データに共通する特徴量の分布を再現することです。特徴量がモデル訓練に用いた作品の表現と関連した何らかの情報を含み、その結果、類似したデータ(コンテンツ)の出力が可能になります。ところが、分布を見ても、個々の作品の「保護される情報」を具体的に指摘することは困難です。特定の著作物Cをモデル訓練に使ったからといって、生成AIの訓練済みモデルが、この作品Cの「保護される情報」を明示的に持つわけではないです。「類似性」のあるコンテンツが出力されたとしても、それは偶然かもしれないです。その生成AIを利用してコンテンツ生成することが、直ちに著作物Cに依拠するとはならないです。
訓練データ記憶という実験から得られる知見(第13回ニュースレターを参照)を重ね合わせると、生成AIを利用することは依拠性を示唆するように思えてきます。一方で、全ての訓練データが必ず記憶されるわけではないので、やはり、「生成AI利用≠依拠」、として良いようです。
特定アーティストの学習データ
次に、モデル訓練に、特定アーティストの作品だけを集めた学習データを用いる場合を考えましょう。今、多様なデータを用いて訓練した基盤モデルがあるとします。この基盤モデルに少数個の新しいノードを付加※1し、特定アーティストの学習データを用いてファインチューニングします。基盤モデルが既に基本的な画像処理機能を持つ一方、この後段開発の結果、特定アーティストの作品に関わる情報を追加したモデルを得ることができます(図参照)。
※1:技術用語でLoRAと呼ぶ手法です。
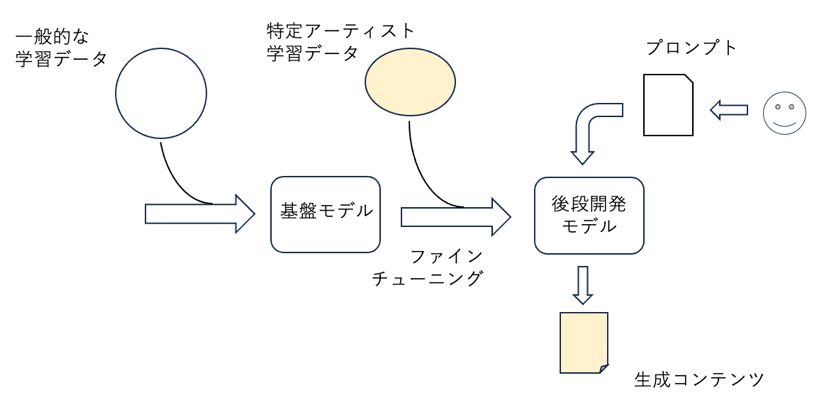
一般に、ファインチューニングは通常の学習と同じように情報解析であり、学習データ利用に際して著作権者の利用許可を必要としません。一方、文化庁の文書(文献[2]20頁)は、「享受目的」が併存する場合、著作権法30条の4が適用されない、つまり、利用許可が必要としています。
ファインチューニングの技術的な性質によると、後段モデルは追加した学習データを過学習し、訓練に用いたデータを高い精度で再現する場合のあることがわかっています。先の例では、特定アーティストの作品を選択的に集めてモデルを訓練したことになり、後段開発作業そのものに享受目的があると判断される可能性があるのです。つまり、このような後段開発モデルを利用してのコンテンツ生成では、類似性だけではなく、依拠性も肯定され、利用者が著作権違反とされる可能性があります。
スタイル模倣
生成AIの技術によって著名なアニメのキャラクターや画風を模倣した生成コンテンツを容易に作成することが可能になっています。実際、スタイルを模倣したコンテンツが大量に流布され、アニメ作成者に不利益を生じていることが話題になりました。
一般に、画風やスタイルはアイデアとされます。「表現・アイデア二分論」から、アイデアは著作権保護の対象になりません(文献[1]第II部第1章)。図のような方法で、アニメの作風などスタイル模倣を可能とするモデルを開発し利用しても、これは著作権法の枠組みの外側のことです。著作権侵害の議論が成り立たないことになるようですが、何となく納得できないですね。
文化庁の文書によると、先の「享受目的」の情報解析と同様に、作風(アイデア)の模倣を目的とするモデル訓練を禁止すると解釈しています(文献[2]21頁)。要点は特定アーティストの学習データが少数という点に着目することです。その少ない量の作品群は、アイデアレベルの作風が共通しているだけではなく、創作的表現(著作権の対象)が共通する作品群であると考えます。そして、生成AIに出力させることを意図したファインチューニングには、享受目的が併存します。利用許可なく無断で2次利用することになり、著作権侵害になります。
市場の希釈化
文化庁の文書にしたがって、著作権30条の4が適用されない場合の議論を見てきました。次に、米国のフェアユース法理からの話題を紹介します。前回のニュースレターでは、フェアユースの4要件の1番目(利用の目的および性格)に関して「変容力のある出力」について考えました。最近、4番目(利用される著作物の潜在的な市場に与える影響)に関係した「市場の希釈化(Market Dilution)」が問題になっています(文献[3]64-66頁)。
「市場の希釈化」は、オリジナル作品に関連した市場に、大量の生成コンテンツが溢れることで、著作意欲が低下する状況を指します。たとえば、生成AIによる探偵小説が増加すると、短い期間に大量の小説を出版する競争相手が登場し、作家の創作意欲が低下します。あるいは、特定の作品との類似性が小さくても、その作者の作風・スタイルを模倣した絵画が大量に出回ると、もとの作者の作品が市場で不利になるでしょう。米国の議論では、生成AIの技術進展とともに、今後、フェアユースの要件として「市場の希釈化」の観点が大きくなるとしています。
生成AIは、専門知識を必要としない手軽さで、短時間に大量のコンテンツを生成可能にする技術です。著作権に関わる問題だけでなく、さまざまな領域で新しい問題を生じており、このニュースレターでも、引き続き関連する話題を取り上げる予定です。
参考文献
[1] 作花文雄:詳解著作権法[第6版]、ぎょうせい (2022).
[2] 文化審議会著作権分科会法制度小委員会「AIと著作権に関する考え方について」(令和6年3月).
[3] U.S. Copyright Office: Copyright and Artificial Intelligence, Part 3: Generative AI Training, pre-publication version (May 2025).
次回の予告
著作物の学習データ利用を避ければ著作権侵害を避けることが可能な場合もあります。中島先生の第15回ニュースレターでは、そのような実務上の工夫を紹介、解説いただきます。お楽しみに。
中島震先生、山口高平先生のニュースレターバックナンバーはこちら
中島先生の著書はこちらです
■「AIアルゴリズムからAIセーフティへ」
中島 震 (訳) (原著:O.サントス, P.ラダニエフ)
丸善出版 2025年3月 (ISBN: 9784621310328)
■「AIリスク・マネジメント」
中島 震
丸善出版 2022年12月 (ISBN: 9784621307809)
■「ソフトウェア工学から学ぶ機械学習の品質問題」
中島 震
丸善出版 2020年11月 (ISBN: 9784621305737)